IAEN Manual
IAEN: Interfaz Gráfica de Usuario para Introducción al Análisis de Redes Ecológicas
Tabla de contenido
- 1 Introducción
- 2 Dependencias
- 3 Cargar la interfaz
- 4 Importación de datos
- 5 Métricas o Estadísticas
- 6 Presentación de gráficos
- Referencias
1 Introducción
Con la finalidad de hacer accesibles a todos los usuarios a las distintas rutinas del lenguaje R para el análisis estadístico de redes y sus gráficas sin la necesidad de un conocimiento en programación se programó una interface gráfica para el usuario (GUI).
El paquete IAEN es una herramienta que proporciona una interfaz gráfica de usuario (GUI) la cual está implementada mediante el kit de herramientas GTK+ implementado en el paquete RGtk2 y está almacenado en el repositorio de GitHub. Permite gestionar datos y realizar diferentes tipos de herramientas empleados en el análisis de redes ecológicas, así como de visualización y edición de gráficos. Existe un gran repertorio de paquetes implementados en R que hacen hincapié en el análisis de redes ecológicas para matrices adyacentes binarias, ponderadas y bipartitas. R también cuenta con un conjunto de paquetes que permiten analizar y visualizar diferentes tipos de redes en general, cada uno tiene sus diferentes formas de gestionar las bases de datos.
Por lo mencionado anteriormente, ésta interfaz está integrada por diversos paquetes almacenados en R que hacen énfasis en redes ecológicas y redes en general, permitiéndonos hacer uso de funciones de manera fácil e interactiva sin que el usuario emplee por completo el lenguaje de programación de R. Se emplean métodos básicos y usuales en el que se especifica en cada proceso el paquete que se está utilizando con la finalidad de difundir el uso de R y sus paqueterías, donde si se desea hacer un análisis más específico puede consultar las diferentes funciones incluidas en el entorno R.
Este documento está destinado a auxiliar al usuario en el funcionamiento de la interfaz para hacer uso adecuado de las diferentes herramientas que proporciona. También se describe cada una de las ventanas que la conforman. En general el usuario puede importar bases de datos en la pestaña de “File”, efectuar análisis de redes en la ventana de “Statistics”, crear redes binarias y realizar funciones de mundos pequeños en la ventana de “Simulations” y ejecutar gráficos en la ventana de “Graphs”.
2 Dependencias
La lista de dependencias que se requieren para que la interfaz se ejecute correctamente se enlista en la Tabla 1, así como el motivo para la que fueron utilizados. Cabe mencionar que existe una alta dependencia de los paquetes enaR, cheddar y bipartite debido a que son los paquetes que más hacen énfasis en la temática de redes ecológicas, además de que contienen funciones de interés para nuestro objetivo. Sólo algunas funciones fueron implementadas. Respecto a la realización de gráficos algunos de éstos fueron realizados mediante las funciones por defecto de su paquete, mientras que otros fueron efectuados empleando los paquetes ggplot2, gplots y ggraph para mejorar en algunos casos su resolución.
Tabla 1. Lista de paquetes requeridos
| Paquetería | Descripción |
|---|---|
| RGtk2 (Lawrence and Temple, 2010) | Herramientas para la creación de interfaces gráficas |
| cairoDevice (Lawrence, 2017) | |
| enaR (Lau et al., 2017) | Funciones para análisis redes ecológicas |
| cheddar (Hudson et al., 2018) | |
| bipartite (Dormann et al., 2008) | |
| readxl (Wickham and Bryan, 2018) | Importación y exportación de datos |
| writexl (Ooms, 2018) | |
| network (Butts, 2015) | Funciones para análisis de redes en general |
| igraph (Csardi and Nepusz, 2006) | |
| sna (Butts, 2016) | |
| tnet (Opsahl, 2009) | |
| ggplot2 (Wickham, 2016) | Funciones para la edición y visualización de gráficos |
| ggraph (Pedersen, 2018) | |
| gplots (Warnes et al., 2016) | |
| scales (Wickham, 2017) | |
| reshape (Wickham, 2007) | Reestructura de datos |
| pryr (Wickham, 2018) | Crear enlaces activos |
3 Cargar la Interfaz
Una vez que se llevó a cabo el proceso de instalación del paquete y verificado que se haya realizado exitosamente, los pasos que prosiguen son los siguientes: en primer lugar hay que cargar el paquete y posteriormente utilizar la función correspondiente para poder visualizar la interfaz. La instalación sólo se realiza una vez en cada versión instalada de R o en su caso R-Studio, así como para cargar el paquete sólo se hace una vez en cada espacio de trabajo abierto, tal como se muestra a continuación:
library(IAEN)
IAEN()
 |
 |
|---|---|
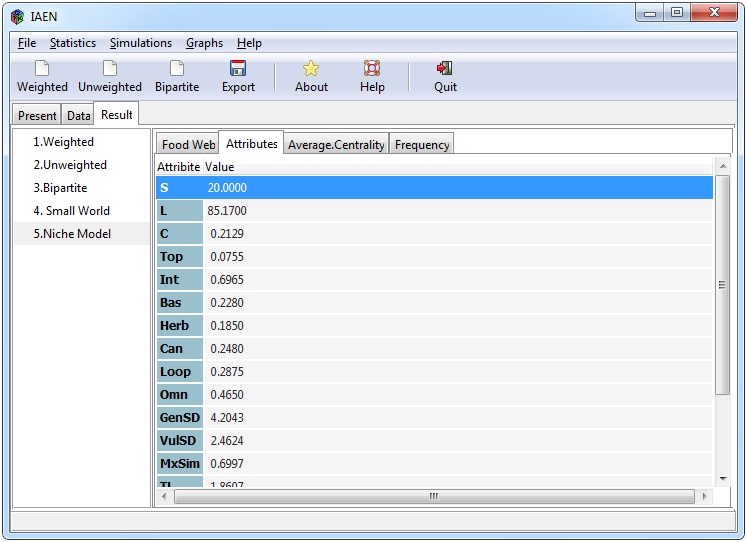 |
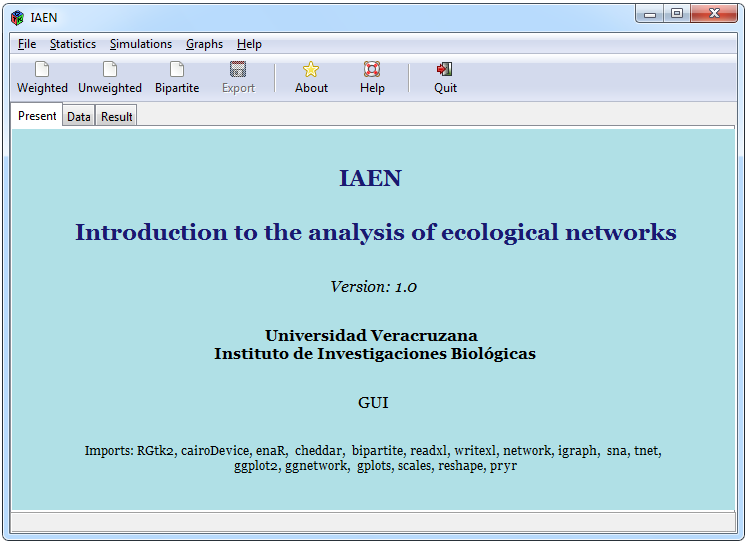
Figura 1. Interfaz gráfica de usuario
En la Figura 1 se ilustra la estructura interactiva de la interfaz gráfica cuando ha sido cargada en la consola de R-Studio donde se observa que los elementos que la componen son una barra de menú, una barra de accesos directos para opciones rápidas de importación y exportación de datos, un conjunto de pestañas que incluye una presentación, una pestaña llamada ”Data” donde se pueden visualizar los datos que han sido cargados y una pestaña nombrada ”Result” donde a través de sub-pestañas se muestran las diferentes salidas de los análisis realizados.
En la barra de menú se muestran diferentes pestañas agrupadas por el tipo de funciones tales como la pestaña de ”File” que contiene funciones de importación y exportación de datos. La pestaña de ”Statistics”, contiene funciones de análisis de datos para las diferentes tipos de redes (binaria, ponderada y bipartita). La pestaña de ”Simulation” muestra una ventana con opciones para crear diferentes tipos de redes alimenticias y realizar funciones utilizadas en mundos pequeños. La pestaña de ”Graphs” muestra una gama de gráficos que se pueden realizar para los diferentes tipos de redes. Por último la pestaña de ”Help” proporciona información general del paquete.
4 Importación de datos
- Matriz adyacente de una red ponderada
Antes de cargar una matriz ponderada hay que tener en cuenta la estructura en la que se requiere que estén organizados los datos. Dicha estructura está basada en los argumentos de entrada requeridos en la función enaR::pack para crear un objeto de clase red y para poder cargarla y visualizarla en la interfaz interactiva se requieren las siguientes especificaciones:
– Nombres de matriz de adyacencia iguales para filas y columnas, preferentemente no numérica y sin espacios.
– Contener valores numéricos.
– Evitar celdas vacías.
– Incluir una columna que especifique los nodos vivos (1) y los no vivos (0).
– Vectores de entradas, exportaciones, salidas, respiraciones, biomasas y vivos deben ser colocadas verticalmente a la matriz de adyacencia y en ese orden.
– La columna “Outputs” es la suma de respiraciones y exportaciones, este vector es opcional.
– La matriz adyacente, el vector de entradas, exportaciones y el vector de vivos son obligatorios, los demás pueden o no considerarse. En caso de no considerarlos incluir un vector de ceros para evitar valores vacíos.
–En el orden de los datos se coloca primero la matriz adyacente, posteriormente en las columnas siguientes las entradas (Inputs), exportaciones (Exports), salidas (Outputs), respiraciones (Respiration), biomasas (Biomass) e indicador de nodos vinos o no vivos (Living).
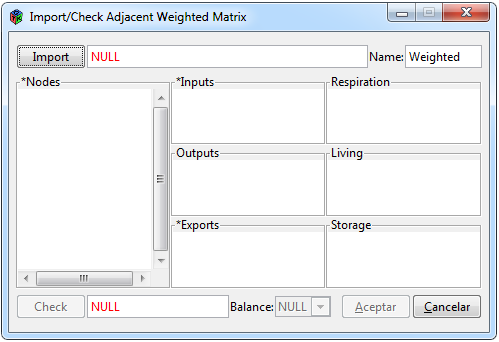
Figura 2. Ventana para importar una matriz ponderada
Para poder importar una matriz ponderada dentro de la interfaz se tiene que seleccionar las pestañas Data> Import> Weighted, siguiendo éstos pasos aparecerá una ventana como la Figura 2, donde los elementos que la conforman son un grupo de secciones que tienen la finalidad de mostrar que los vectores cargados estén en el orden adecuado. La funcionalidad de la ventana está resumida en los siguientes pasos:
– Buscar el archivo a través del botón “Import”, donde se podrá elegir archivos con formato Excel (.xls), Excel delimitado por comas (.csv) o texto (.txt).
– Poner nombre al nuevo objeto, por defecto Weighted.
– Los primeros vectores de la matriz aparecerán en la sección de “Nodes”.
– En automático se acomoda el resto de vectores en cada una de las secciones.
– “Matrix”, “Input “y “Export” son obligatorias, las demás entradas son opcionales.
– Verificar con el botón “Check” que todos los vectores están importados correctamente, en caso de ser incorrecto se mostrará una ventana emergente con la lista de errores encontrados, posteriormente revise el formato de entrada de los datos para corregir los detalles.
– La pestaña de balanceo se activará sólo en caso de que la matriz y los vectores restantes no estén balanceados, de ser el caso seleccionar el tipo de balanceo que se quiera ejecutar, dicha función está retomada de la función enaR::balance.
– Por último seleccionar el botón “Ok” para que diferentes objetos sea creados y puedan ser utilizados cuando sea necesario, a su vez se imprimirán los datos en la pestaña de “Data”.
- Matriz adyacente de una red no ponderada
Respecto a la matriz no ponderada las especificaciones son diferentes, entre ellas se destaca que su estructura es binaria donde los valores que la conforman deben ser numéricos y únicamente se deben incluir valores con ceros y unos donde cero representa ausencia de interacción depredador-presa y uno representa presencia de interacción depredador-presa. Se tiene que evitar valores vacíos y se debe de incluir nombres de filas y columnas donde dichos nombres de preferencia no deben tener espacios y deben ser simétricos.
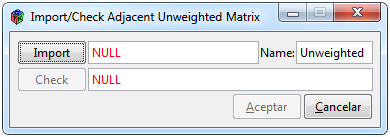
Figura 3. Ventana para importar una matriz no ponderada
Para importar una matriz adyacente no ponderada o dicho de otra forma una matriz binaria, se debe seleccionar las pestañas Data> Import> Unweighted desde la interfaz, al hacer esto se abrirá una ventana como la de la Figura 3. El botón de ”Import” tiene la funcionalidad de abrir una ventana para buscar el archivo que se desea importar, donde el formato a elegir puede ser de Excel (.xls), Excel delimitado por comas (.csv) o texto (.txt).
Se puede cambiar nombre de la matriz, por defecto Unweighted, dicho nombre servirá para nombrar diferentes objetos que se emplearán en los análisis posteriores y para identificarla dentro de la interfaz. Una vez seleccionado un archivo se activará el botón ”Check” el cual tiene la finalidad de revisar el cumplimiento de las especificaciones anteriormente mencionadas donde si no cumple al menos una, aparecerá una ventana emergente para mostrar los errores que se hayan encontrado, de ser éste el caso se tiene que revisar y corregir los datos de entrada.
- Matriz adyacente de una red bipartita
Los pasos a seguir para importar una matriz bipartita son muy parecidos a los de una matriz binaria, ya que las especificaciones son: incluir nombres de filas y columnas preferentemente sin espacios, evitar valores vacíos y contener valores numéricos ya sean binarios (ceros y unos) o ponderados. La única diferencia es que puede ser de dimensión pxq ya que éste tipo redes no necesariamente tienen que ser simétricas debido a que no representan interacciones tróficas.
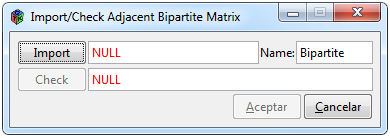
Figura 4. Ventana para importar una matriz bipartita
Por otra parte, para importar una matriz adyacente bipartita se deben seleccionar las pestañas Data> Import> Bipartite. La ventana resultante (Figura 4) es semejante a la de una matriz no ponderada, sólo que el nombre por defecto es Bipartite y las especificaciones que evalúa el botón ”Check” son diferentes. El botón ”Import” tiene la misma funcionalidad de mostrar una ventana para buscar el archivo que se desea cargar con opciones de formato de Excel (.xls), Excel delimitado por comas (.csv) o texto (.txt). Al hacer clic en “Aceptar”, se crearán los objetos necesarios para poder realizar los análisis que se soliciten posteriormente y se visualizarán los datos en la interfaz en la pestaña de ”Data”.
5 Métricas o Estadísticas
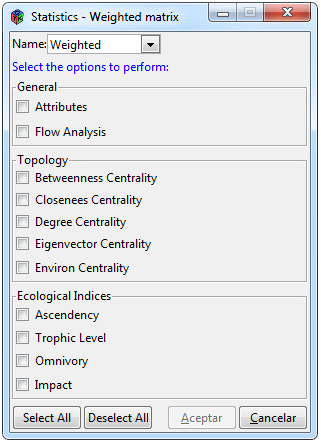
Figura 5. Estadísticas para una red ponderada
Para realizar diferentes estadísticas de una red ponderada se tiene que seleccionar las pestañas Statistics> Weighted, posteriormente aparecerá la ventana de la Figura 5. La pestaña de Weighted se activará solo cuando se haya importado en la interfaz una matriz adyacente de una red ponderada. La ventana está dividida en tres secciones, la sección de ”General” que contiene métricas de la red como lo son atributos y análisis de flujos, la sección de ”Topology” que contiene un conjunto de centralidades diferentes y el apartado de ”Ecological Indices” que contiene indicadores específicos para una red trófica. La Pestaña ”Name” muestra el nombre de todas las redes ponderadas que han sido cargadas en la interfaz, se tiene que seleccionar la red con la que se desea realizar los análisis.
Algunos atributos y las centralidades de closeness, betweenness y degree fueros utilizadas empleando el paquete tnet, mientras que las otras centralidades y las demás funciones que hacen hincapié en análisis de redes ecológicas se realizan mediante el paquete enaR. Para conocer la descripción de cada resultado favor de ver la documentación de los paquetes tnet (Opsahl, 2009) y enaR (Lau et al., 2017).
Por último, contiene un conjunto de botones para seleccionar y deseleccionar todas las categorías incluidas, y un botón de aceptar y cancelar la corrida de los análisis. Al hacer clic en aceptar aparecerá un ícono de carga en la parte inferior izquierda de la interfaz con el fin de notificar que algunos análisis pueden requerir largo tiempo de espera, posteriormente se mostrarán los resultados en la ventana de ”Result” a través de sub-pestañas.
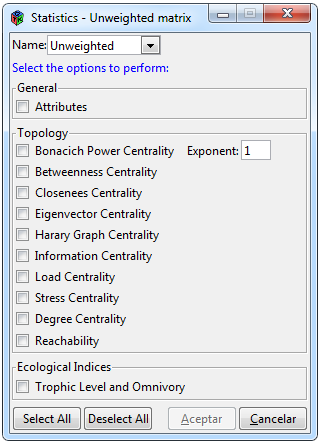
Figura 6. Estadísticas para una red no ponderada
Para realizar diferentes estadísticos de una red no ponderada hay que seleccionar las pestañas Statistics> Unweighted dentro de la interfaz, cabe mencionar que dicha pestaña solo se activa cuando se ha importado una matriz adyacente de éste tipo. La ventana está dividida en tres secciones ”General”, ”Topology” y ”Ecological Indices” (Figura 6). Para el cálculo de atributos se emplearon los paquetes cheddar, igraph y network. En atributos se agregaron tres funciones sencillas, una que calcula el porcentaje de especies herbívoras, otra que muestra el porcentaje de especies que están incluidas en loops o ciclos el cual fue obtenido identificando los nodos incluidos en la diagonal de la multiplicación de la misma matriz n veces y por último la proporción de especies que se alimentan de presas de más de un nivel trófico.
En el apartado de ”Topology” se muestra un grupo de centralidades así como la función de reachability, las centralidades de betweenness, closeness y degree fueron utilizadas emplendo el paquete igraph, mientras que las demás se utilizaron empleando el paquete sna. La sección de ”Ecological Indices” contiene los cálculos del nivel trófico e indicadores de omnivoría para ello se empleó paquete cheddar, se incluyó un indicador de omnivoría mencionado por Goldwasser and Roughgarden (1993) el cual se basa en la media de las desviaciones estándar de las longitudes de cadena de cada especie hasta una especie basal.
La pestanña de ”Name” muestra todas las matrices binarias que han sido cargadas a la interfaz de las cuales se tiene que seleccionar alguna para realizar los análisis. Para ver las especificaciones de cada resultado favor de consultar la documentación de igraph (Csardi and Nepusz, 2006), sna (Butts, 2016), cheddar (Hudson et al., 2018) y network (Butts, 2015). De la misma forma que en la ventana de la Figura 6 se incluyen botones de seleccionar y deseleccionar las casillas y un botón de aceptar y cancelar, en el que al hacer clic en el botón de aceptar se incluirá un ícono en la parte inferior izquierda que indica que el programa está ejecutando los algoritmos correspondientes y al finalizar aparecerán los resultados en sub-pestañas en el apartado de ”Result”.
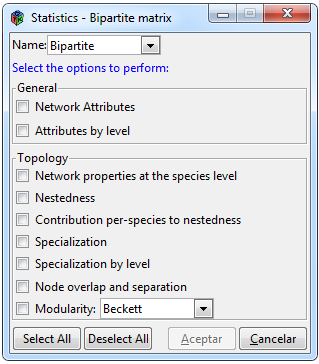
Figura 7. Estadísticas para una red bipartita
Para efectuar estadísticos de una red bipartita hay que seleccionar las pestañas Statistics>Bipartite, dicha pestaña se activará solo cuando se haya importado en la interfaz una matriz adyacente de una red bipartita. Al hacer clic en las pestañas anteriores apare-cerá una ventana como la de la Figura 7. La ventana está seccionada en dos partes, la primera contiene atributos generales de la red y la segunda llamada ”Topology” contiene funciones más específicas, ambos apartados incluyen funciones del paquete bipartite (Dormann et al., 2008) por lo que para conocer el contenido de cada indicador favor de revisar la descripción de las funciones en su documentación.
De la misma forma que en las ventanas de las Figuras 6 y 7 se incluye una pestaña de ”Name” para seleccionar la red con la que se desea ejecutar las funciones y se incluyen botones de seleccionar y deseleccionar las casillas y un botón de aceptar y cancelar con las mismas funcionalidades.
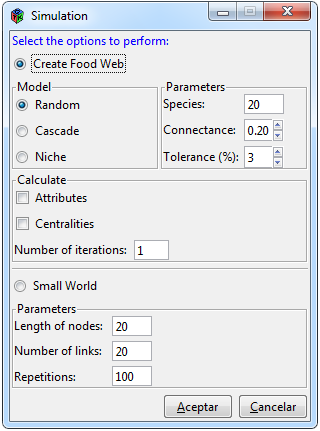
Figura 8. Ventana de simulación
Para realizar diferentes funciones de simulación se tienen que seleccionar las pestañas de Simulations> Simulations y así visualizar la ventana mostrada en la Figura 8. La ventana contiene dos secciones una para crear redes alimenticias aleatorias y otra para ejecutar funciones empleadas en redes de mundos pequeños. Posee tres métodos para crear redes alimenticias, el modelo aleatorio, el modelo de cascada y el modelo de nicho, de los cuales se puede calcular los atributos y centralidades, a su vez se puede realizar éste procedimiento n veces y como resultado se obtendrá una matriz aleatoria y el promedio de atributos y centralidades de las n repeticiones, también se incluye una matriz con el número de veces que una interacción apareció en una posición específica.
Los modelos de redes alimenticias poseen como argumento el número de nodos o especies, el valor de la conectividad en una escala de 0 a 1 y un valor de porcentaje de tolerancia que hace referencia al intervalo de aceptación para la conectividad, es decir, en cada simulación la función sólo incluye redes que estén en ese intervalo del parámetro con la finalidad de que el parámetro sea consistente, tal como se menciona en Williams and Martinez (2000), por defecto 3%.
El modelo aleatorio (Williams and Martinez, 2000) estaá basado en el modelo de Erdos and Rényi (1960), el cual consiste en crear una red con n vértices representando el número de especies (S), donde todos los enlaces entre especies tienen la misma probabilidad P de existir igual a la conectividad (C) de la red empírica. En el modelo de cascada (Cohen and Newman (1985); Williams and Martinez (2000)), cada especie tiene una probabilidad P=2CS/(S-1) de consumir otra especie con valores de nicho más bajos. El modelo tiene una jerarquía estricta de alimentación ya que prohíbe la presencia de canibalismo y ciclos.
El modelo de nicho Williams and Martinez (2000) asigna a cada especie un valor de nicho (ni) en el intervalo [0,1]. Cada especie se alimenta de las especies que se encuentran en el rango de valores de nicho (ri) obtenidos de la distribución beta, los cuales son colocados mediante un valor de centro ci, permitiendo la presencia de canibalismo y bucles. El centro ci del rango de alimentación ri es un número aleatorio uniforme en el intervalo de ri/2 y el valor mínimo entre ni y 1-ri/2. Para garantizar que cada red contenga al menos una especie basal, la especie con el valor de ni maás pequeño tiene valor de rango igual a cero.
Los algoritmos de los tres modelos anteriormente mencionados fueron implementados en la interfaz gráfica a través de algoritmos propios, donde se agregan funciones que evitan la presencia de nodos con dobles ceros y/o desconectados.
Por otro lado, en la segunda sección se incluye el cálculo de la longitud del camino característico (L) y el coeficiente de cluster (C), ambos parámetros son empleados para contrastar si una red se comporta o no como un mundo pequeño (Watts and Strogatz, 1998). Para la creación de los grafos aleatorio se empleó la función igraph::sample_gnm que genera grafos de acuerdo con el modelo de Erdos-Renyi, para el coeficiente de cluster se utilizó la función igraph::transitivity y para la longitud promedio del camino más corto la función igraph::mean_distance, las tres funciones pertenecen al paquete igraph (Csardi and Nepusz, 2006).
Los argumentos requeridos en la interfaz gráfica para obtener los parámetros L y C son el número de nodos, el número de enlaces y el número de repeticiones que se desea realizar para optimizar el resultado. Como resultado se obtiene una tabla con los valores de L y C de cada una de las repeticiones así como el promedio. Al hacer clic en el botón de aceptar aparecerán los resultados en la pestaña de ”Result” a través de sub-pestañas ya sea de la creación de redes alimenticias o de los parámetros de mundos pequeños.
6 Presentación de gráficos
Cada gráfico contiene una ventana con un apartado de opciones que contiene diferentes parámetros básicos que se pueden alterar para la realización de los mismos, los más comunes es el tamaño de letra y de nodo, así como el color de letra y de los nodos. Varios gráficos tienen también por argumento el especificar si se quiere emplear el nombre original de los nodos o si se desea sustituir por números y en algunos casos sólo se puede utilizar números para identificar el nodo o únicamente puntos, depende del tipo de gráfico que se desea realizar, esto con la finalidad de no saturar el gráfico y que se pueda apreciar mejor los resultados.
La cantidad de parámetros que se muestran en cada ventana dependerá del tipo de gráfico que se desee realizar. Además, contiene una pestaña que muestra las diferentes redes que han sido cargadas en la interfaz, si se desea correr un gráfico específicamente de una red no ponderadas entonces sólo aparecerán los nombres de ese tipo de red. En la parte inferior derecha de cada ventana se incluyen los botones de aceptar y cancelar.
Se puede abrir una ventana de un gráfico seleccionando el menú de gráficos luego el tipo de red y por último el tipo de gráfico a realizar. Inicialmente las pestañas aparecen inactivas, para activarla se tiene que importar una red del mismo tipo. El menú de gráficos contiene el nombre de la función original de la paquetería que fue empleada con la finalidad de que el usuario pueda identificar la función correspondiente y saber que procedimiento se está llevando a cabo, dichos paquetes ya se mencionaron anteriormente. Todas las ventanas de los gráficos tienen en la parte superior izquierda, un par de botones un botón de guardar y otro de salir, también incluye una pestaña para seleccionar el formato en el que se desea guardar, entre los formatos disponibles se encuentran tiff, jpeg, png y eps.
 |
 |
|---|---|
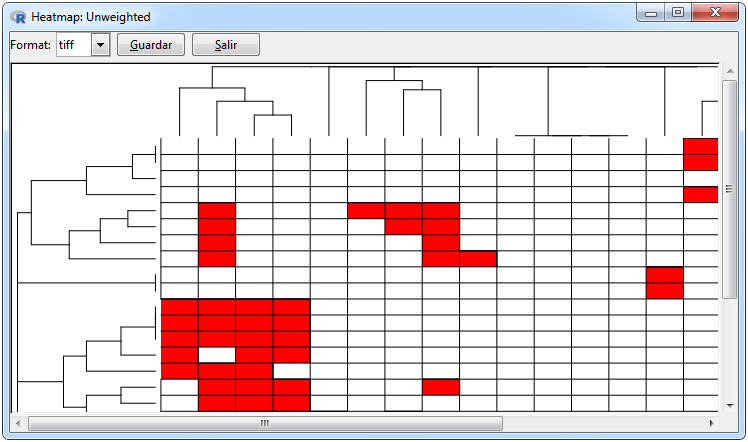 |
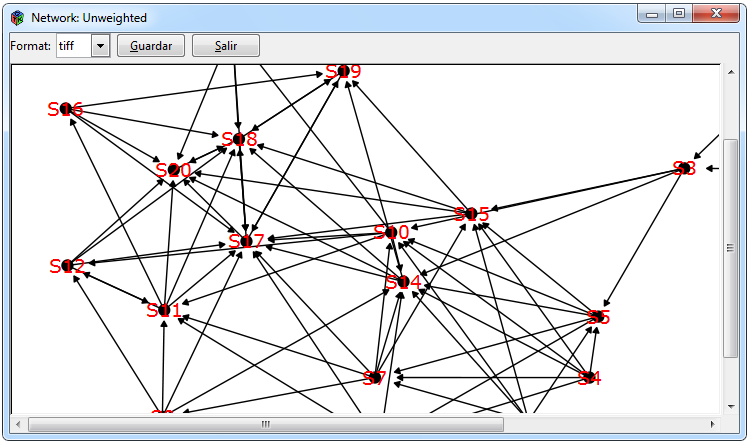
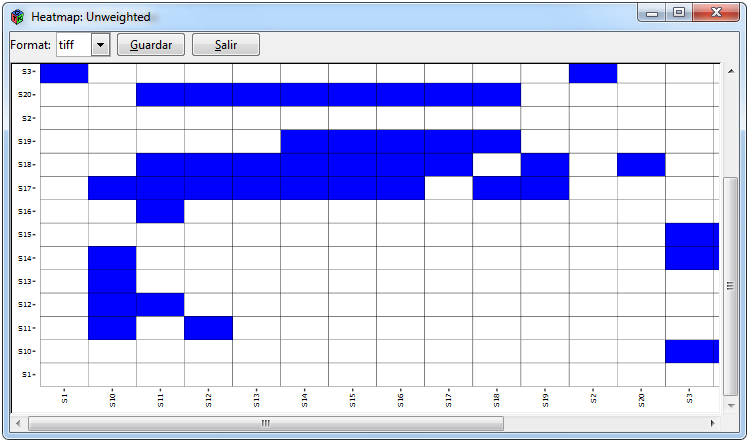
Figura 9: Gráficos para cualquier tipo de red
En la Figura 9 se muestran los gráficos que se pueden realizar para cualquier tipo de red importada. Para la red se empleó el paquete ggraph que contiene funciones para graficar redes a través de ggplot2, donde si la matriz es bipartita los nodos se ordenan diferente. Las pestañas para realizar una red es Graph>Network> gplot. Los otros dos gráficos son mapas de calor que tienen la finalidad de representar gráficamente la matriz adyacente en el que se tienen que seleccionar las pestañas Graph> Heat map>ggplot/heatmap.2 para poderlos realizar.
Uno de los argumentos para realizar un mapa de calor es si se desea incluir cluster para filas y columnas o no. En el primer caso del mapa de calor con cluster se empleó la función headmap.2 del paquete gplot, además por defecto si la matriz adyacente es binaria emplea la distancia de Jaccard y el método de Ward, mientras que si la matriz adyacente es ponderada se utiliza la distancia euclidiana y el método de Ward. En el caso de que sólo se desee graficar el mapa de calor, se emplea el paquete ggplot2.
 |
 |
|---|---|
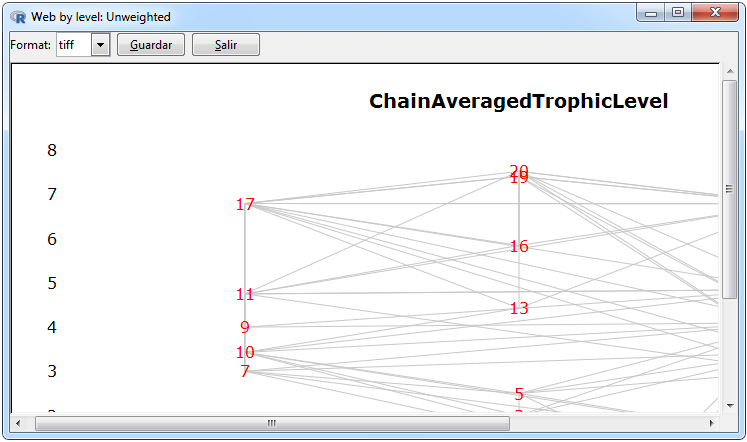 |
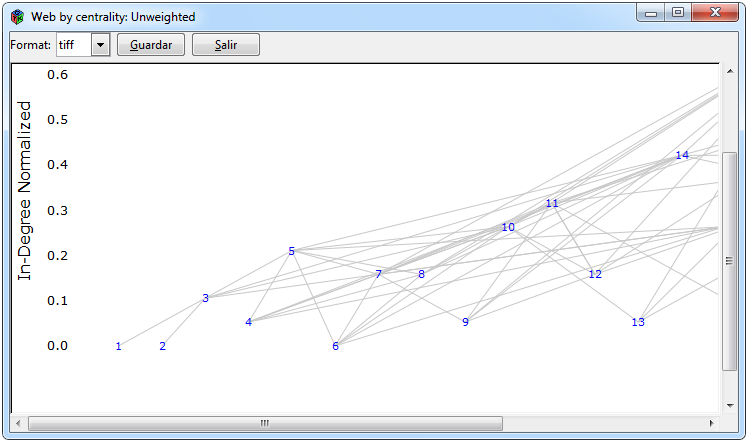
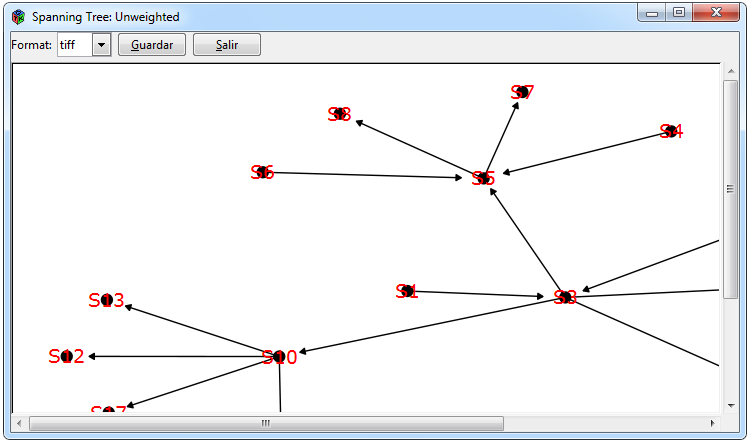
Figura 10. Gráficos para una red no ponderada
En la Figura 10 se muestran los gráficos que se pueden realizar para una red ponderada. Los gráficos de la red ordenada con respecto a alguna centralidad y mediante los niveles tróficos fueron empleados mediante la función por defecto del paquete cheddar uno mediante la función cheddar::PlotNPS y otro mediante la función cheddar::PlotWebByLevel, las pestañas para realizarlos son Graphs> Unweighted Matrix> Centrality> PlotNPS y Graphs> Unweighted Matrix> Web By Level> PlotWeb- ByLevel respectivamente. Para el cálculo de spanning tree se empleó la función igraph::mst del paquete igraph y para graficarlo el paquete igraph mediante las pestañas Graphs> Unweighted Matrix> Spanning Tree> mst.
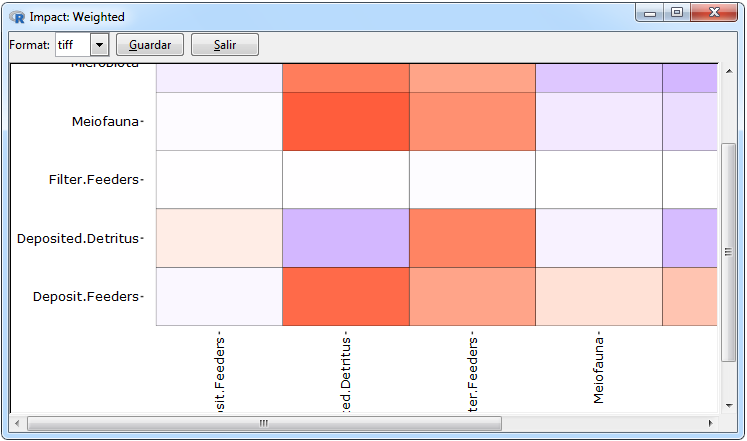
Figura 11. Gráfico de impacto para una red ponderada
En el caso de las redes ponderadas, el único gráfico incluido además de la red y el heatmap para representar la matriz adyacente es un mapa de calor realizado con funciones del paquete ggplot2 para representa los impactos tróficos totales de una especie sobre otra mediante el algoritmo de Ulanowicz and Puccia (1990) implementado en el paquete enaR a través de la función enaMTI. Se incluye como argumento el color para valores negativos y positivos donde si los valores estén próximos a cero el color correspondiente se degradará hasta el color blanco. Un ejemplo de éste tipo de gráficos se muestra en la Figura 11 donde para poderlo realizar se tienen que seguir las siguientes pestañas Graph> Weighted> Impact> ggplot.
 |
 |
|---|---|
 |
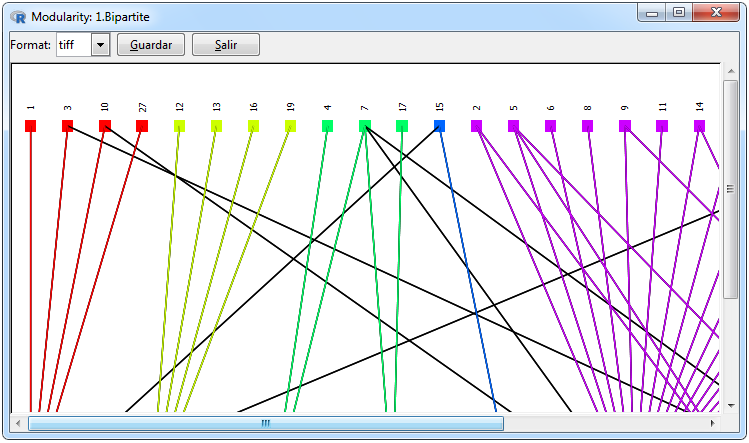 |
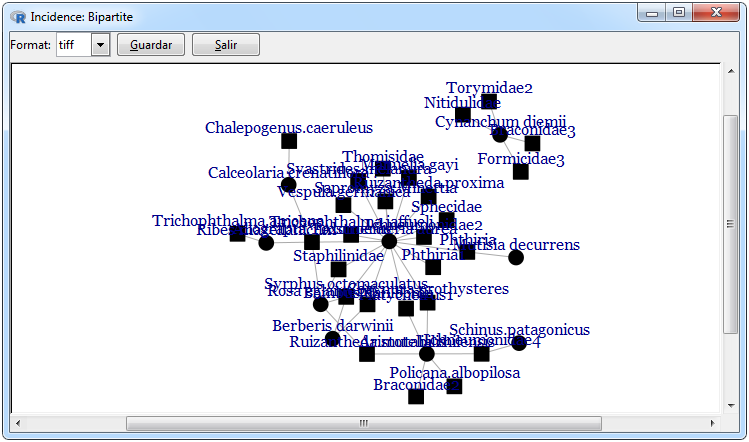
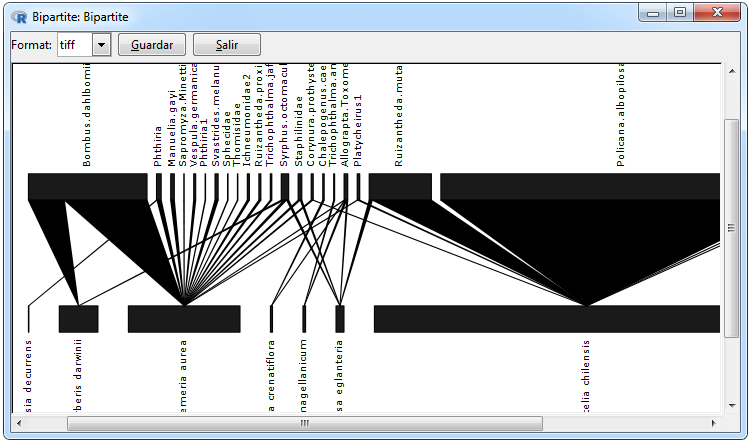
Figura 12. Gráficos para una red bipartita
En la Figura 12 se muestran los gráficos que se pueden realizar para una red bipartita, el primero es una red de incidencia el cual hace una distinción a través de las figuras para diferencias las filas y columnas de la matriz adyacente, dicho gráfico fue utilizado empleando el paquete igraph mediante la función graph.incidence y se puede realizar mediante las pestañas Graphs> Bipartite Matrix> Network> graph.incidence. La red bipartita se utilizó empleando el paquete bipartite ya que es una forma clara de visualizar las ponderaciones en éste tipo de redes y se puede realizar mediante las pestañas Graphs> Bipartite Matrix> Plot Web> plotweb.
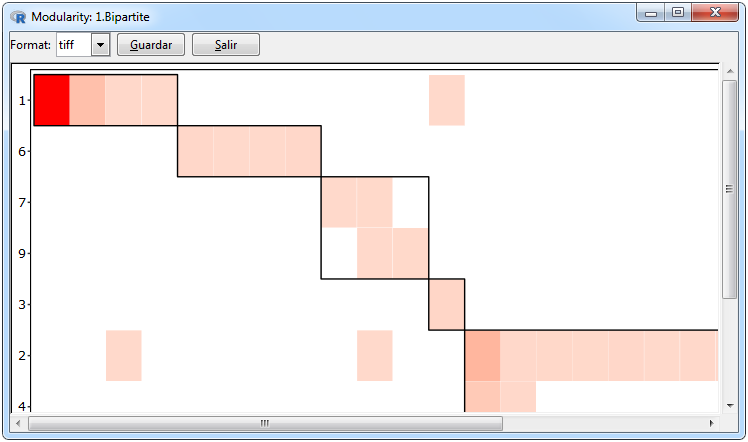
Para la visualización de la modularidad de la red se emplearon dos formas, una mediante un heatmap donde a través de una cuadricula se diferencian los cluster y otra mediante una red con los nodos ordenados respecto al grupo al que pertenecen en el que para diferencias un grupo de otro se utilizó un gama de colores diferentes, ambos gráficos se realizaron empleando el paquete ggplot2 y se pueden realizar a través de las pestañas Graphs> Bipartite Matrix> Modularity> ggplot. En la realización de un gráfico de modularidad primero se tiene que hacer el cálculo en la ventana de estadísticas para una red bipartita el cual empleará la función bipartite::computeModules. La ventana del gráfico en vez de mostrar una pestaña con los nombres de las redes bipartitas importadas mostrará el id de los resultados de modularidad que estén en los resultados.
Referencias
Butts, C.T. (2015). network: Classes for Relational Data. R package version 1.13.0.1. The Statnet Project (http://statnet.org). url: http://CRAN.R-project.org/package=network.
Butts, C.T. (2016). sna: Tools for Social Network Analysis. R package version 2.4. url: https://CRAN.R-project.org/package=sna.
Cohen, J.E. and C.M. Newman (1985). “A stochastic theory of community food webs I. Models and aggregated data”. In: Proc. R. Soc. Lond. B 224.1237, pp. 421-448.
Csardi, G. and T. Nepusz (2006). “The igraph software package for complex network research”. In: InterJournal Complex Systems, p. 1695. url: http://igraph.org.
Dormann, C.F., B. Gruber, and J. Fruend (2008). “Introducing the bipartite Package: Analysing Ecological Networks”. In: R News 8.2, pp. 8-11.
Erdos, P. and A. Renyi (1960). “On the evolution of random graphs”. In: Publ. Math. Inst. Hung. Acad. Sci 5.1, pp. 17-60.
Goldwasser, L. and J. Roughgarden (1993). “Construction and analysis of a large Caribbean food web”. In: Ecology 74.4, pp. 1216-1233.
GTK+ (2007). The Gimp Tool Kit. url: http://www.gtk.org/.
Hudson, L., D. Reuman, and R. Emerson (2018). Cheddar: analysis and visualization of ecological communities. R package version 0.1-633. url: https://github.com/quicklizard99/cheddar/.
Lau, M.K. et al. (2017). enaR: Tools for Ecological Network Analysis. R package version 3.0.0. url: https://CRAN.R-project.org/package=enaR.
Lawrence, M. (2017). cairoDevice: Embeddable Cairo Graphics Device Driver. R package version 2.24. url: https://CRAN.R-project.org/package=cairoDevice.
Lawrence, M. and D. Temple (2010). “RGtk2: A Graphical User Interface Toolkit for R”. In: Journal of Statistical Software 37.8, pp. 1-52. url: http://www.jstatsoft.org/v37/i08/.
Makiyama, K. (2018). githubinstall: A Helpful Way to Install R Packages Hosted on GitHub. R package version 0.2.2. url: https://CRAN.R-project.org/package=githubinstall.
Ooms, J. (2018). writexl: Export Data Frames to Excel ‘xlsx’ Format. R package version 1.0. url: https://CRAN.R-project.org/package=writexl.
Opsahl, T. (2009). Structure and Evolution of Weighted Networks. University of London (Queen Mary College), London, UK, pp. 104-122. url: http://toreopsahl.com/publications/thesis/.
Pedersen, T.L. (2018). ggraph: An Implementation of Grammar of Graphics for Graphs and Networks. R package version 1.0.2. https://CRAN.R-project.org/package=ggraph.
Ulanowicz, R.E. and C.J. Puccia (1990). “Mixed trophic impacts in ecosystems”. In: Coenoses, pp. 7{16.
Warnes, G.R. et al. (2016). gplots: Various R Programming Tools for Plotting Data. R package version 3.0.1. url: https://CRAN.R-project.org/package=gplots.
Watts, D.J. and S.H. Strogatz (1998). “Collective dynamics of `small-world’networks”. In: nature 393.6684, p. 440.
Wickham, H. (2007). “Reshaping data with the reshape package”. In: Journal of Statistical Software 21.12. url: http://www.jstatsoft.org/v21/i12/paper.
Wickham, H. (2016). ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. isbn: 978-3-319-24277-4. url: http://ggplot2.org.
Wickham, H. (2017). scales: Scale Functions for Visualization. R package version 0.5.0. url: https://CRAN.R-project.org/package=scales.
Wickham, H. (2018). pryr: Tools for Computing on the Language. R package version 0.1.4. url: https://CRAN.R-project.org/package=pryr.
Wickham, H. and J. Bryan (2018). readxl: Read Excel Files. R package version 1.1.0. url: https://CRAN.R-project.org/package=readxl.
Wickham, H., J. Hester, and W. Chang (2018). devtools: Tools to Make Developing R Packages Easier. R package version 1.13.6. url: https://CRAN.R-project.org/package=devtools.
Williams, R.J. and N.D. Martinez (2000). “Simple rules yield complex food webs”. In: Nature 404.6774, p. 180.